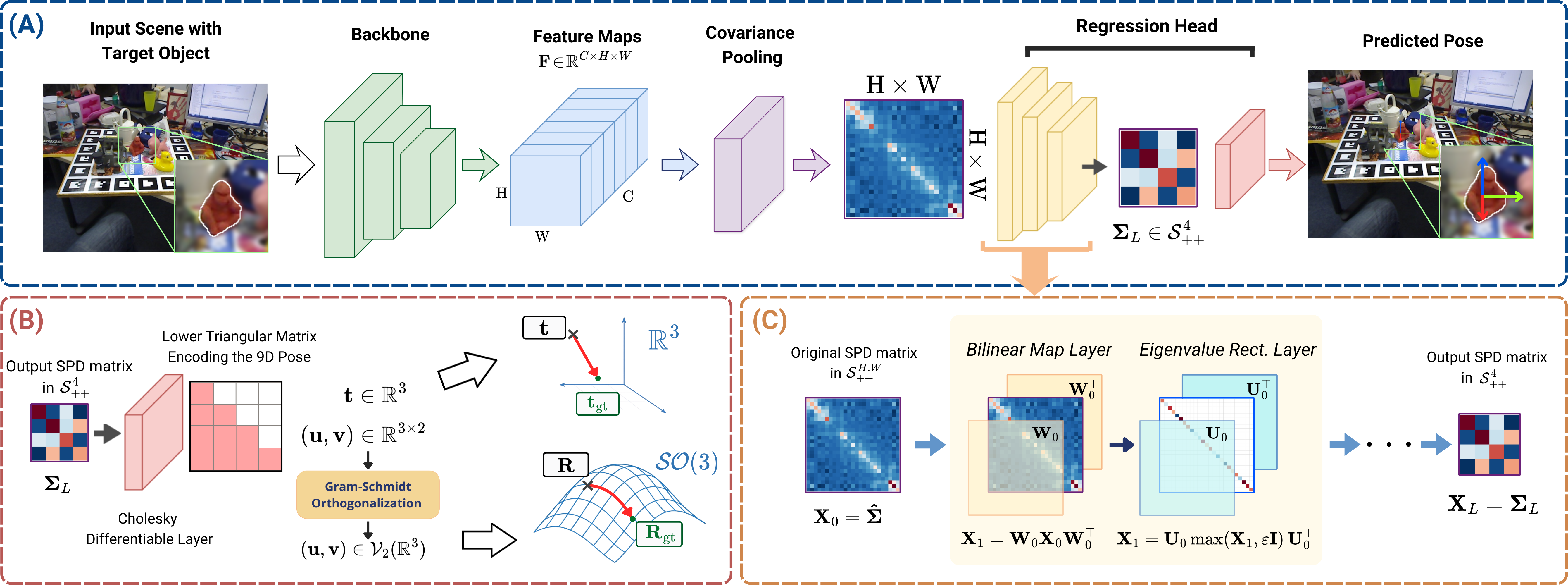
Estimating the 6-DoF pose of an object from a single RGB image is a central problem in computer vision, robotics, augmented reality, and autonomous systems. While many methods rely on intermediate correspondences, keypoints, or refinement stages, Cov2Pose follows a direct pose regression paradigm.
The key idea behind Cov2Pose is to enrich the pose regression pipeline with spatial
second-order statistics. Instead of relying solely on first-order or globally pooled features, Cov2Pose uses a covariance-based
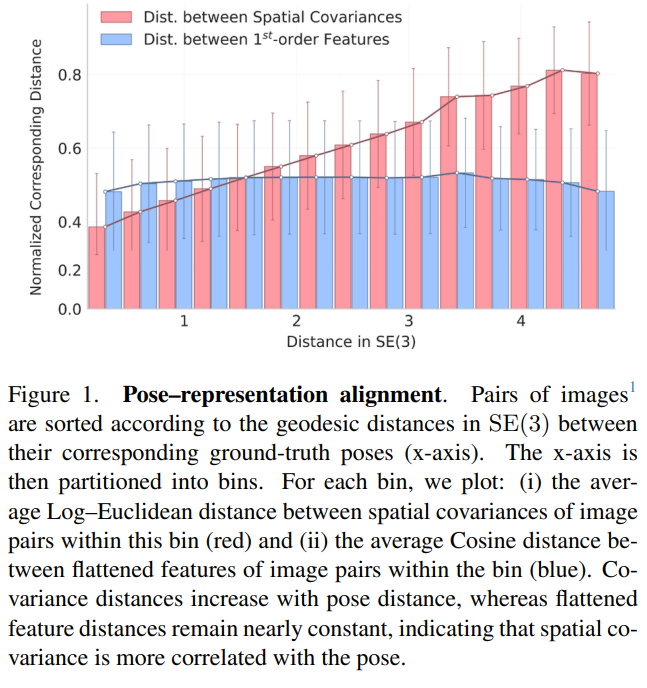
representation that more effectively captures spatial relationships between regions in the input image, as shown in the figure above. Cov2Pose further introduces a manifold-aware formulation for pose regression by encoding
pose information through symmetric positive definite representations. This allows the
network to learn pose predictions in a geometry-aware representation space. The main contributions can be summarized as follows,
- The first covariance-based deep learning framework for RGB-based end-to-end 6-DoF object pose regression, which leverages the spatial covariance of backbone features to encode higher-order statistics.
- A manifold-aware training pipeline that applies geometry-preserving dimensionality reduction using Bilinear Mapping layers (BiMap) [1] to learn a compact SPD representation.
- A fully differentiable, CAD-free, one-to-one, and continuous pose regressor that maps the latent SPD matrix to a continuous 6D rotation representation and translation via a differentiable Cholesky decomposition.
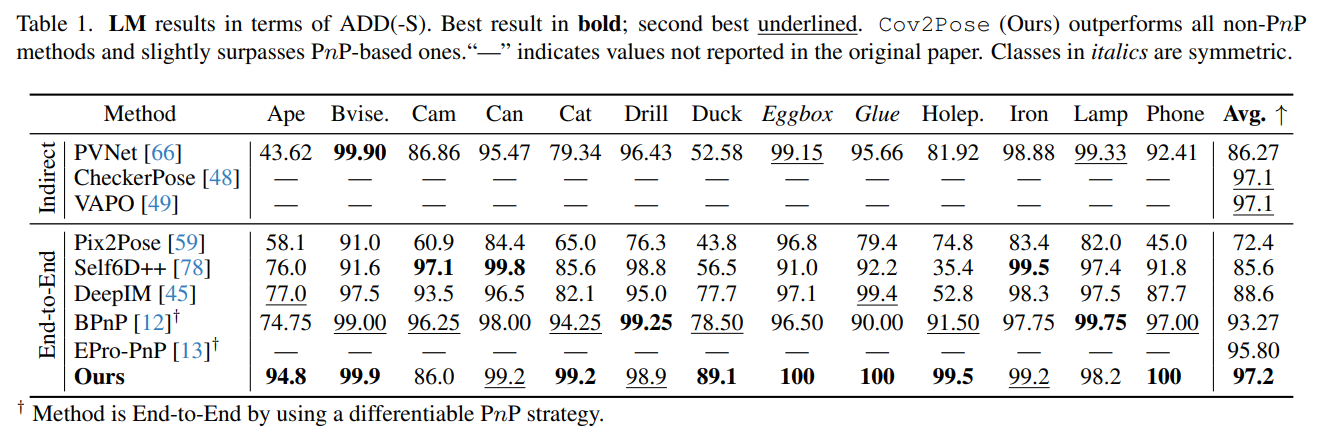
- Extensive experiments on three object pose benchmarks, namely, LineMOD [2], Occ-LineMOD [3] and YCBVideo [4], showing that
Cov2Pose achieves state-ofthe-art results as compared to direct regression methods.